PinnedPooja MahajaninThe StartupData Quality- The Unsung HeroWhile many MOOCs educate starting from the basics of machine learning techniques to deep learning algorithms using toy datasets that are…4 min read·Oct 9, 2020----
PinnedPooja MahajaninCodeXAI in Healthcare -Closer Look!In this article, I will be taking you through some of the practical considerations and challenges of using AI in Medical diagnosis. The…3 min read·Apr 7, 2021----
Pooja MahajaninThe StartupScratching the surface of ML DeploymentIn this article we will be discussing some of the deployment considerations and patterns. Deployment being the last step of machine…3 min read·Aug 14, 2021----
Pooja MahajanUnderstanding Avoidable Bias!In this article, we will discuss comparing our model accuracy with human-level performance and discuss the concepts like avoidable bias and…2 min read·May 18, 2021--1--1
Pooja MahajaninTowards DevTransfer Learning using PyTorchTransfer learning implies adapting a network trained for one problem to a different problem. It is common to pre-train a CNN on a very…3 min read·Mar 16, 2021----
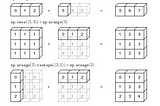
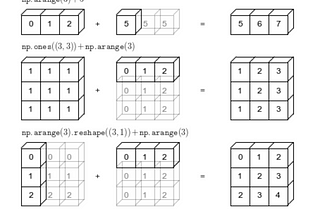
Pooja MahajanBroadcasting in PythonIn this post, we will discuss ‘Broadcasting’ using NumPy. It is also used while implementing neural networks as these operations are…3 min read·Nov 18, 2020----
Pooja MahajanImage Filters with ConvolutionsUsing scipy for practical implementation in Python2 min read·Nov 12, 2020----
Pooja MahajaninThe StartupFully Connected vs Convolutional Neural NetworksImplementation using Keras4 min read·Oct 23, 2020--2--2
Pooja MahajaninAnalytics VidhyaCOVID Tweet Analysis — Part 3Building a Sentiment Classifier4 min read·Oct 8, 2020----