Getting started with Deep Learning
This is my first post to get started with fundamental terms of deep learning .Deep learning is one of the hottest tech topic in the market right now .We often hear about recommendation engines , face recognition ,object detection ,chat-bots ,voice recognition etc , all of these amaze us with the functionality they are able to provide using deep learning techniques.

So let’s start this journey by getting understanding of few terminologies that you may encounter .
Concepts covered:-
- Convolutions and Kernels
- Channels and Multi-Channel Convolutions
- Receptive Field
So let’s start the warm-up :D
- Convolution and Kernels

So what is happening here !!
We have an image of size 5*5 , a 3*3 matrix is sliding over this 5*5 to produce an output of 3 *3 . Let’s dig deep into this flat image. 😛
Convolution is a mathematical operation, definition says it is a way to combine two functions to get third function , so what it means in our context :-
- first function is the input image (5*5)
- second function is 3*3 matrix sliding over the image
- the output or the third function is the green image(3*3).
Let’s understand what all happened to 5*5 to become 3*3 .

- Blue image (5*5) is the initial input image.
- 3*3 matrix sliding over the image does element wise multiplication with the hovered 3*3 matrix of image underneath it and adds up all the multiplications to get one final value and slides to the next 3*3 matrix of the input image (with stride 1) .
- Green image (3*3) is the output ,also called Layer .

Now that you have understood the process that how this operation is being done , let’s get acquainted with the terminology .
We have an input image of size N * N , a matrix of size k*k slide over the image to give an output of size T*T . The matrix that is sliding over the image to perform convolution operation is called “Kernel”.
These are also called filters that helps us to draw out features from the image. They are implemented as matrices ,kernel moves over the input layer and for each step a product with the elements of kernel and the sub part of image values is performed and summed up for each of the pixel in output layer then the kernel strides and performs the same operation.
2. Channels
So now that you have understood the concept of convolutions and how kernel plays it’s role in convolution operations , let’s talk about one more concept — “Channels” .

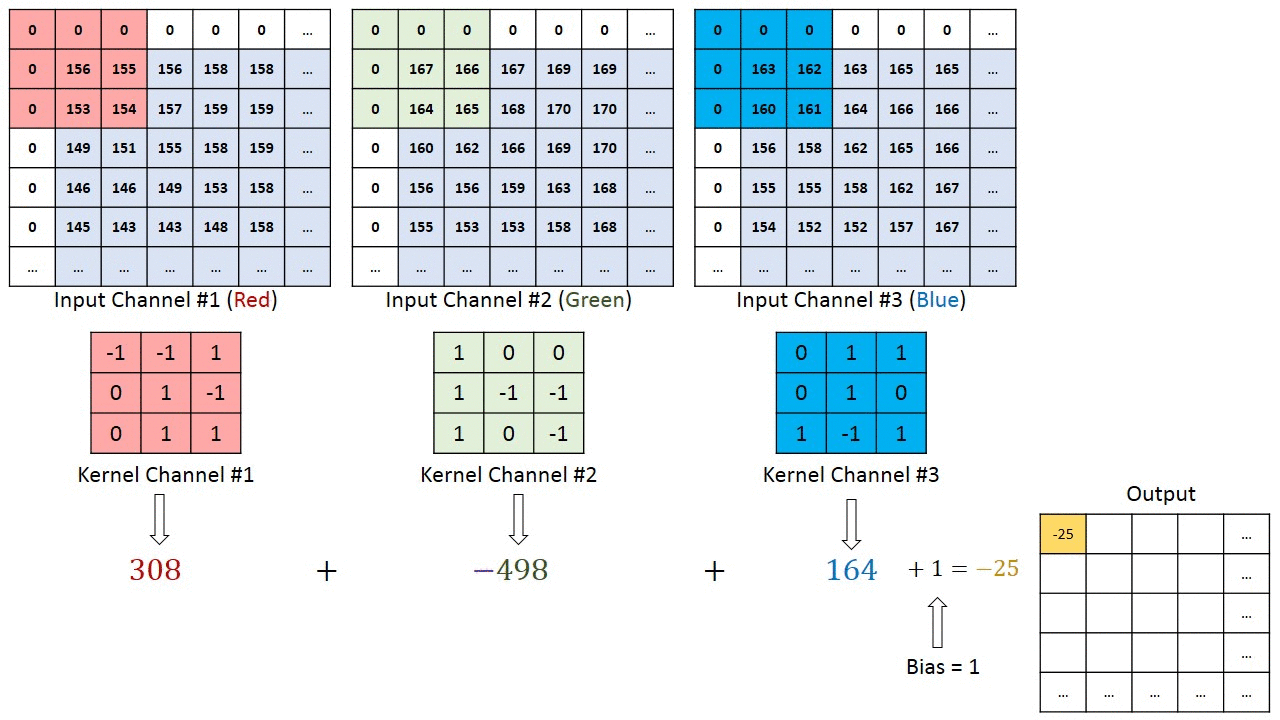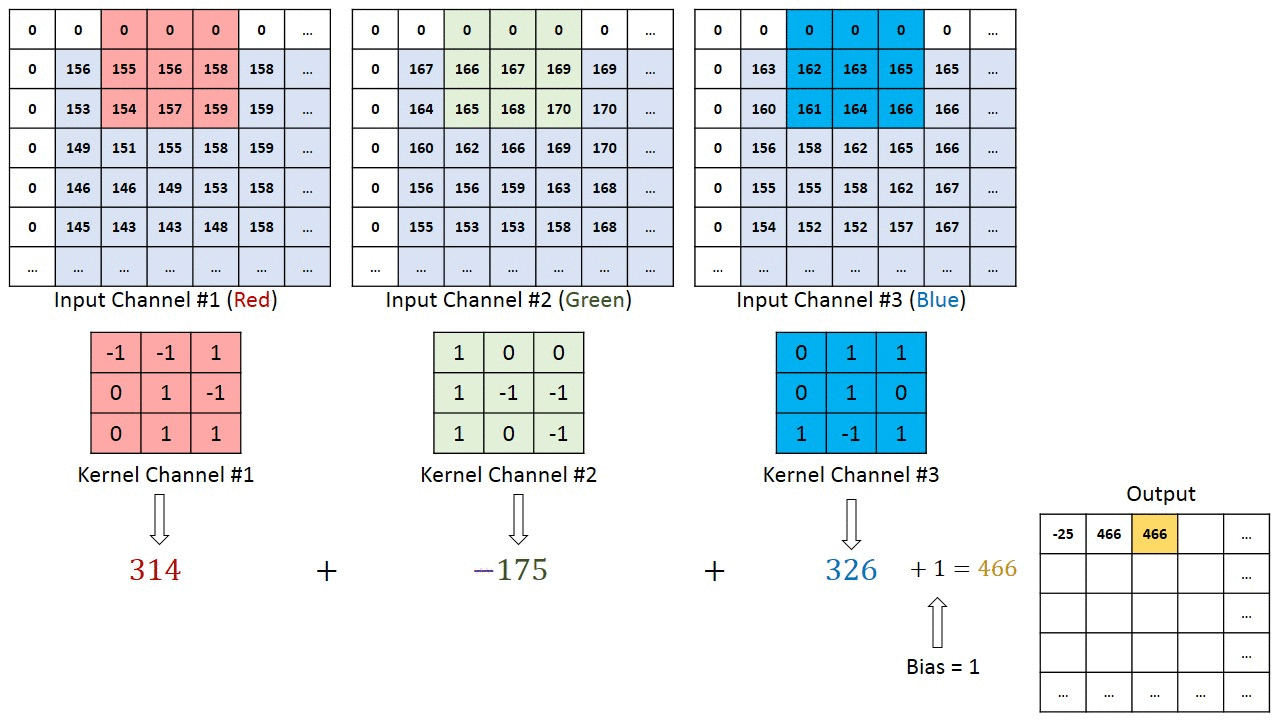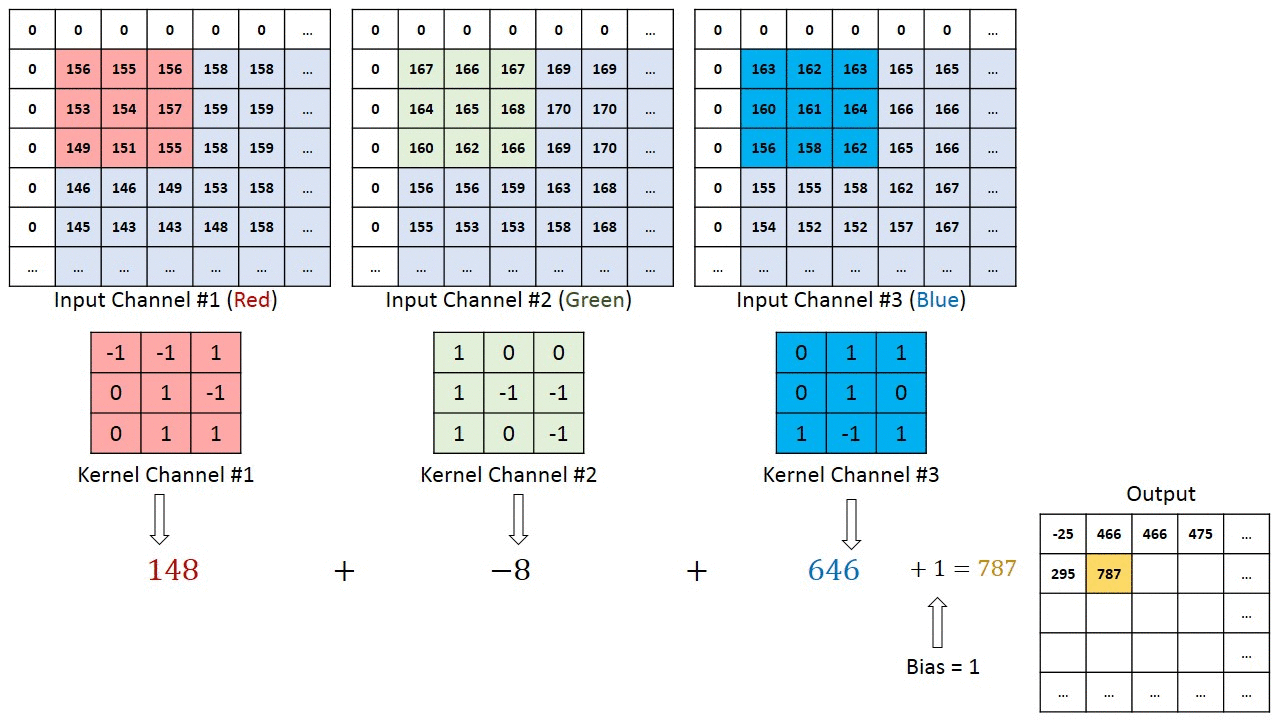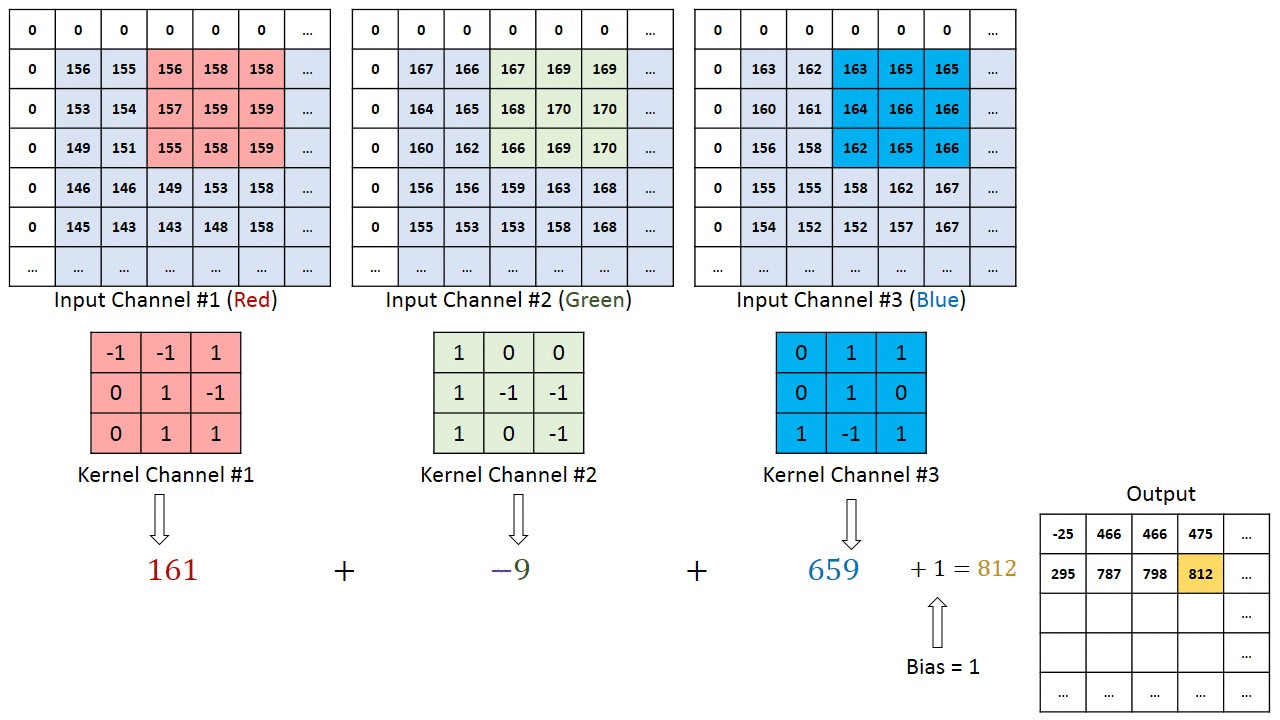
To understand about channels , let’s take an example of RGB image . RGB stands for Red Green and Blue channels .RGB image is composition of 3 channels.
Each of the channels in each pixel represents the intensity of each color that constitute that pixel.
Note :-A gray-scale image has one channel .
Now the question arises if we have RGB image as input for convolution , how kernel will perform the computations .
To answer this, we have a concept called “Multi Channel Convolution”.
That means we will have kernels with equal number of channels as image and the convolution operation will be performed channel wise and all the outputs will be summed up together to get a final output .
So that is how channels are important in the process of Convolutions .
3.Receptive Fields
Now that we are clear with concepts of kernels and channels in Convolution process , let’s talk about one more interesting concept — Receptive Field .

The receptive field in a convolutional neural network refers to the part of the image that is visible to one filter at a time.
These are of two types :-
- Local Receptive Field
- Global Receptive Field
For Layer-1 every time kernel is convolving over the input image and populating each pixel of the Layer -1, each pixel has view of 3*3 pixels of input layer which is the receptive field(local as well as global in this case).
So when we say Layer-1 has receptive field of 3*3 it means each pixel of Layer-1 has seen 3*3 pixels of the input layer .
For layer-2 —
Local receptive field is 3*3 because kernel convolved over Layer-1 3*3 values Global receptive field is 5*5 because the pixels of Layer-1 on which after convolving we got Layer-2 ,have seen the input image pixels as well .
So in nutshell :- Single pixel in Layer-2 has full view of 5*5 image therefore global receptive field is 5*5.
In practice we use global receptive fields .
I hope this gives the clear intuition behind the concepts of Convolutions , Kernels ,Channels and Receptive Field to get started with Deep Learning.
For further info stay tuned!!
